

Performance and Scalability Essentials for Web API Beginners
Covering key concepts that beginners to Web API development need to know in order to ensure their APIs are performant and scalable.
Basic idea
In this post, I'll explain some basic concepts about the Performance and Scalability of Web APIs in general. This one here is more of a beginner's guide, so if you already have some considerable experience, It will be more of the same for you.
To Explain the concepts, I'll use a simple Web API made in Node with Express. Here is the initial code:
import express from "express";
import cors from "cors";
const recursiveCalcFib = (n: number): number => {
if (n <= 1) return n;
return recursiveCalcFib(n - 1) + recursiveCalcFib(n - 2);
};
const app = express();
app.use(cors());
app.use(express.json());
app.get("/fib", async (req, res) => {
const { number } = req.query;
const fibNumber = recursiveCalcFib(Number(number));
return res.status(200).json({ result: fibNumber });
});
app.listen(3000, async () => {
console.log("server running at 3000");
});
So here we have a simple endpoint called '/fib' that receives a number from query params and return the Fibonacci of this number, I'm using Fibonacci because depending on the number, the node runtime may take a while to calculate the result, so this is enough to simulate something with some CPU cost.
So if I use some library like Artillery to do load testing on this API endpoint making 100 concurrent requests per second for 10 seconds, passing the number 30 in the param running locally on my PC, the results will be something like this:
{
"duration": 10,
"total requests": 1000,
"concurrent requests per second": 100,
"min response time in ms": 6,
"max response time in ms": 49,
"median resposne time in ms": 12.1,
"succed requests": 1000,
"failed requests": 0
}
It's ok. But 100 concurrent requests per second for only 10 seconds is a little. So what happens if we increase those numbers?
So here are the results of making 1000 concurrent requests per second for 10 seconds, passing the number 30 in the param using the same environment:
{
"duration": 10,
"total requests": 10000,
"concurrent requests per second": 1000,
"min response time in ms": 16,
"max response time in ms": 9776,
"median resposne time in ms": 5826.9,
"succed requests": 1707,
"failed requests": 8293
}
So, if we increase just one zero on the concurrent requests per second number, we already get poor results. The API is basically unusable with those values, so how can we improve that?
Big O
The first thing we can do is look at our endpoints implementation and see if we're doing something terribly wrong for performance or if we can improve the general performance of the endpoints. Here we have a super valuable concept to measure functions/methods performance in general, called Big O notation, so what is Big O notation?
Big O notation is a mathematical notation that describes the limiting behavior of a function. In computation that's useful for classifying algorithms according to how their runtime or space requirements grow as the input size grows (yes, I got this description from Wikipedia), let's see some examples:
const addOneToAllNumbers = (arr: number[]): number[] => arr.map(number => number + 1);
Above is a simple function that receives an array of numbers and adds one to all of them, so what is the Big O of this function?
This function's Big O notation is O(n), but what does that mean?
The letter "n" here represents the input size, and the "O" is the order of approximation, so O(n) means that this function will have the same time complexity as the input size. It is also called linearity. For example:
addOneToAllNumbers([1,2,3,4,5]);
If we call this function with an array of 5 elements, the function will have the Big O notation of O(5), which means that the function will iterate five times on runtime to be completed.
Other examples of Big O notation:
-
O(1) also called constant time, means that the time complexity of the function will always be one, independent of the input size
-
O(log(n)) means that the time complexity of the function will be the log calculation of the input size
-
O(n) also called linear time, already explained before
-
O(n ^ 2) means that the time complexity of the function will be the input size ^ 2
-
A lot of other ones
Here you can quickly notice that a function with the Big O notation O(1) can perform massively better than an O(n ^ 2) one depending on input size.
So backing to our API, how can we use this Big O notation knowledge to improve the performance of our fib endpoint?
Looking into our endpoint, we have a function called recursiveCalcFib that receives a number and return the Fibonacci of this number. We're using recursion here to implement this function. If we think about the Big O notation of this function, looking into his implementation, we can quickly notice that the function has O(n ^ 2) time complexity, so let's improve that. Here is a function that does the same thing, but in O(n) time complexity:
const ONCalcFib = (n: number): number => {
let a: number = 0;
let b: number = 1;
let c: number = n;
for (let i = 2; i <= n; i++) {
c = a + b;
a = b;
b = c;
}
return c;
};
So now let's replace the old function with this new one on our API:
import express from "express";
import cors from "cors";
// Old function
// const recursiveCalcFib = (n: number): number => {
// if (n <= 1) return n;
// return recursiveCalcFib(n - 1) + recursiveCalcFib(n - 2);
// };
const ONCalcFib = (n: number): number => {
let a: number = 0;
let b: number = 1;
let c: number = n;
for (let i = 2; i <= n; i++) {
c = a + b;
a = b;
b = c;
}
return c;
};
const app = express();
app.use(cors());
app.use(express.json());
app.get("/fib", async (req, res) => {
const { number } = req.query;
const fibNumber = ONCalcFib(Number(number));
return res.status(200).json({ result: fibNumber });
});
app.listen(3000, async () => {
console.log("server running at 3000");
});
And let's see again the results of making 1000 concurrent requests per second for 10 seconds, passing the number 30 in the param using the same environment:
{
"duration": 10,
"total requests": 10000,
"concurrent requests per second": 1000,
"min response time in ms": 0.7,
"max response time in ms": 72,
"median resposne time in ms": 1,
"succed requests": 10000,
"failed requests": 0
}
As you can see, just turning our old O(n ^ 2) endpoint into an O(n) one, we got a huge performance improvement, and the API is usable now.
But what happens if we try to increase the load testing numbers even more?
So here are the results of making 5000 concurrent requests per second for 30 seconds, passing the number 30 in the param using the same environment:
{
"duration": 30,
"total requests": 150000,
"concurrent requests per second": 5000,
"min response time in ms": 0.7,
"max response time in ms": 6618,
"median resposne time in ms": 340.4,
"succed requests": 117823,
"failed requests": 32177
}
As you can see now, making 5000 concurrent requests per second for 30 seconds, we already start to get some bad results, but let's improve that.
Multithreading
Ok, this topic here cannot be applied in any programming language since we have a lot of languages that do not have built-in support for multithreading, but if you are using one of these languages, don't worry. The next topic will show what you can do in this case.
So what multithreading means? Multithreading is the ability of a CPU to provide multiple threads of execution concurrently. With some languages like Rust, Elixir, and Haskell, for example, we can use that to create a "multithreaded app," which means that this app will have multiple threads executing in a shared address space.
We're using Node here as an example, and the Node runtime is single-threaded, but we have a thing we can do in Node, and I'll use this here to demonstrate multithreading. I'm talking about NodeJs clustering (clustering in Node is not exactly multithreading like you do in other languages, but I'll not talk about it because this is not the topic of this post).
So let's rewrite our API using NodeJs clustering:
import express from "express";
import cors from "cors";
import { cpus } from "os";
import cluster from "cluster";
const ONCalcFib = (n: number): number => {
let a: number = 0;
let b: number = 1;
let c: number = n;
for (let i = 2; i <= n; i++) {
c = a + b;
a = b;
b = c;
}
return c;
};
const totalCPUs = cpus().length;
if (cluster.isPrimary) {
for (let i = 0; i < totalCPUs; i++) {
cluster.fork();
}
cluster.on("exit", () => {
cluster.fork();
});
} else {
const app = express();
app.use(cors());
app.use(express.json());
app.get("/fib", async (req, res) => {
const { number } = req.query;
const fibNumber = ONCalcFib(Number(number));
return res.status(200).json({ result: fibNumber });
});
app.listen(3000, async () => {
console.log("server running at 3000");
});
}
And now let's see again the results of making 5000 concurrent requests per second for 30 seconds, passing the number 30 in the param using the same environment:
{
"duration": 30,
"total requests": 150000,
"concurrent requests per second": 5000,
"min response time in ms": 0.7,
"max response time in ms": 199,
"median resposne time in ms": 1,
"succed requests": 150000,
"failed requests": 0
}
And again, colossal performance improvement :D
Infrastructure and load balancing
If you're using a language that does not have runtime support for multithreading, you can run multiple single-threaded apps and coordinate them using a load balancer. Besides that, you can also use load balancing to coordinate multiple multithreaded apps too, running on various computers.
So what is a load balancer?
A load balancer is a device that acts as a reverse proxy to distribute and coordinate application traffic across multiple servers, like in the image below:
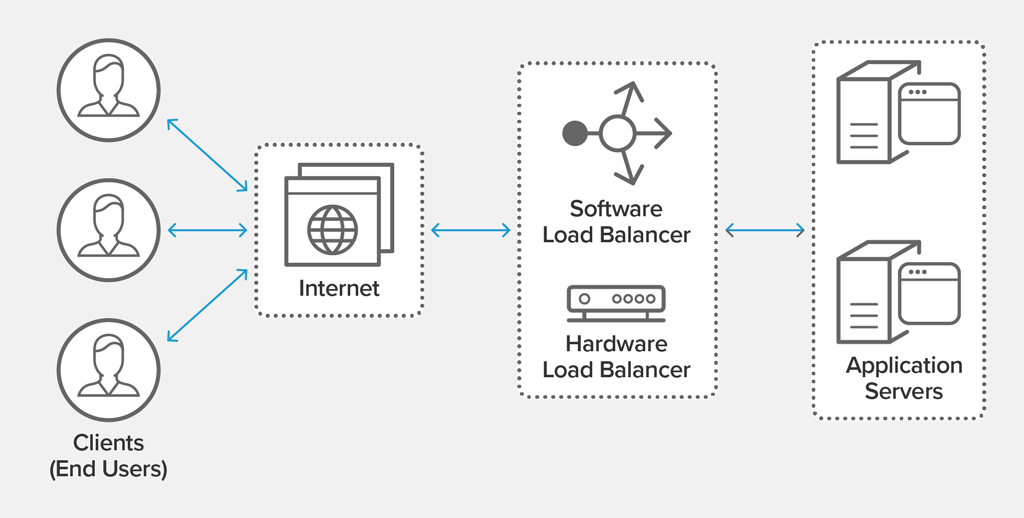
So if you want, you can code your own load balancer, but I'll use NGINX in this post. NGINX is an efficient web server that can also be used as a load balancer. You can install NGINX here.
So let's leave our API implementation using NodeJs clustering for now and go back to the single-threaded one:
import express from "express";
import cors from "cors";
const ONCalcFib = (n: number): number => {
let a: number = 0;
let b: number = 1;
let c: number = n;
for (let i = 2; i <= n; i++) {
c = a + b;
a = b;
b = c;
}
return c;
};
const app = express();
app.use(cors());
app.use(express.json());
app.get("/fib", async (req, res) => {
const { number } = req.query;
const fibNumber = ONCalcFib(Number(number));
return res.status(200).json({ result: fibNumber });
});
app.listen(3000, async () => {
console.log("server running at 3000");
});
But now, instead of running just one server, we'll run multiple ones. To help with that, I'll use Docker here:
// Dockerfile
FROM node:16
WORKDIR /usr/src/app
COPY package*.json ./
RUN npm install
COPY . .
EXPOSE 3000
CMD ["npm", "run", "dev"]
Using Docker, we can efficiently run multiple servers in multiple ports, so I spawned ten servers on ten ports of my PC using the commands:
sudo docker build . -t api
sudo docker run --name {NAME_HERE} -p {PORT_NUMBER}:3000 -d api
But now we've multiple servers running in various ports, and we need to coordinate all of them, let's use NGINX to do that:
worker_processes auto;
events {
worker_connections 1024;
}
http {
include /etc/nginx/mime.types;
upstream node-api {
server 127.0.0.1:3000;
server 127.0.0.1:3001;
server 127.0.0.1:3002;
server 127.0.0.1:3003;
server 127.0.0.1:3004;
server 127.0.0.1:3005;
server 127.0.0.1:3006;
server 127.0.0.1:3007;
server 127.0.0.1:3008;
server 127.0.0.1:3009;
}
server {
listen 8080;
server_name localhost;
location / {
try_files $request_uri @API;
}
location @API {
proxy_pass http://node-api;
}
}
}
Now using this NGINX config, we have an NGINX server running at 8080 port doing reverse proxy and load balancing of all our servers.
Let's see the results of making 5000 concurrent requests per second for 30 seconds, passing the number 30 in the param using the same environment, but now using our multiple single-threaded servers with NGINX instead of the 'multithreaded' version of our API:
{
"duration": 30,
"total requests": 150000,
"concurrent requests per second": 5000,
"min response time in ms": 0.7,
"max response time in ms": 6959,
"median resposne time in ms": 89,
"succed requests": 150000,
"failed requests": 0
}
Important keep in mind that this is running everything on my local machine. In a real-world application, you may want to use multiple devices running one or more servers to get even better results than the ones I'm showing here.
Caching
The last but not less critical concept that I'll try to explain and demonstrate here is Caching.
In computing, a cache is a high-speed data storage layer so that future requests can be served faster with this data.
A common use case of caching in Web APIs is using an in-memory database like Redis to maintain reusable data between endpoint requests.
For example, let's go back to our first example of API:
import express from "express";
import cors from "cors";
const recursiveCalcFib = (n: number): number => {
if (n <= 1) return n;
return recursiveCalcFib(n - 1) + recursiveCalcFib(n - 2);
};
const app = express();
app.use(cors());
app.use(express.json());
app.get("/fib", async (req, res) => {
const { number } = req.query;
const fibNumber = recursiveCalcFib(Number(number));
return res.status(200).json({ result: fibNumber });
});
app.listen(3000, async () => {
console.log("server running at 3000");
});
The first problem we notice on this API version is that the recursiveCalcFib function we're using to calculate the Fibonacci has lousy time complexity. Let's pretend that we don't know how to optimize it or that we don't have a better implementation of this Fibonacci function, so how can we improve the performance of our endpoint in this case?
In this case, we can use Redis or any other in-memory data structure store to cache the calculation results when they happen the first time, so we don't need to execute the function in all requests.
import express from "express";
import cors from "cors";
import { createClient } from "redis";
const redisClient = createClient({
url: "redis://:@localhost:6379",
});
const recursiveCalcFib = (n: number): number => {
if (n <= 1) return n;
return recursiveCalcFib(n - 1) + recursiveCalcFib(n - 2);
};
const app = express();
app.use(cors());
app.use(express.json());
app.get("/fib", async (req, res) => {
const { number } = req.query;
const cache = await redisClient.get(String(number));
if (cache) {
return res.status(200).json({ result: Number(JSON.parse(cache)) });
} else {
const fibNumber = recursiveCalcFib(Number(number));
await redisClient.set(String(number), JSON.stringify(fibNumber));
return res.status(200).json({ result: fibNumber });
}
});
app.listen(3000, async () => {
await redisClient.connect();
console.log("server running at 3000");
});
If we compare the benchmark results of making 1000 concurrent requests per second for 10 seconds passing the number 30 in the param that was the bench numbers that started to fail on that first version, we'll see really better results:
{
"duration": 10,
"total requests": 10000,
"concurrent requests per second": 1000,
"min response time in ms": 0.7,
"max response time in ms": 214,
"median resposne time in ms": 2,
"succed requests": 10000,
"failed requests": 0
}
And here, caching can help if you have functions/methods in your code that you don't know how to optimize.
A little disclaimer: this example above could be better since we're using memory to store the numbers results, and we can have infinite numbers, but you know it is just a silly example to show the concept.
Another typical example of caching usage in Web APIs are CDNs (Content delivery network).
Almost all APIs that handle assets like images, videos, or webpages will use CDNs to cache content in proxy servers.
Some other useful concepts
Here are some other practical and cool concepts that I'll not enter into detail in this blog post:
Conclusion
In conclusion, optimizing the performance of Web APIs is crucial for delivering fast and responsive web applications by understanding the factors that can impact API performance.
It's also important to regularly monitor and test API performance to identify any bottlenecks or areas for improvement. Using tools like load testing and real-time monitoring, developers can ensure that their API can handle large traffic volumes and respond quickly to user requests.